
PWN-堆利用(堆工作介绍/double free)
堆管理器
堆概述
什么是堆?
- 是虚拟地址空间的一块连续的线性区域
- 提供动态分配的内存,允许程序申请大小未知的内存
- 在用户与操作系统之间,作为动态内存管理的中间人
- 响应用户的申请内存请求, 向操作系统申请内存,然后将其返回给用户程序
- 管理用户所释放的内存,适 时归还给操作系统
申请内存的两种系统调用:
1.brk
brk调用为在data段向上延申一段区域作为申请的内存供程序使用,该调用多发生在进程的主线程调用区域,且该方式申请的内存较小,一般用于小内存申请。
2.mmap
mmap为大内存申请,即brk无法满足所需申请内存的大小,需要操作系统从内存中映射一段内存作为申请的内存供程序使用。
Areana
arena为内存的分配区,可以理解为堆管理器所持有的内存池。
图解:

堆管理器与用户的内存交易发生于arena中,可以理解为堆管理器向操作系统批发来的有冗余的内存库存。
arena起着存储从操作系统中借来但还未交给用户内存或存储用户归还但还未交给操作系统的内存的作用。
Chunk
chunk为用户申请内存的单位,也是堆管理器管理内存的基本单位 malloc()返回的指针指向一个chunk的数据区域。
chunk的基本结构如下:
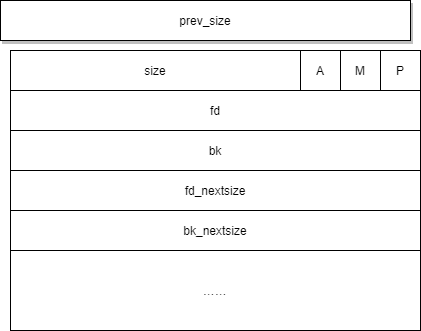
其中,
最下方段为数据段。
prev size和size为控制段,size记录该chunk的大小。 (所有chunk都有的)
fd(指针)在bin中指向下一个(非物理相邻)空闲的 chunk。(fase bin free chunk含有,small和unsorted也有)
bk(指针)在bin中指向上一个(非物理相邻)空闲的 chunk。(small bin free chunk 和unsorted bin free chunk 含有)
fd_nextsize 在large bin中指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针 (只存在large bin)
bk_nextsize 在large bin中指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针(只存在large bin)
补充:
1 .chunk分为malloc chunk(即正在使用的内存区域)和free chunk(即已经释放的内存区域)
对于chunk结构中,
- 若该chunk前一个chunk为free chunk,则prev size 记录的是上一个chunk 的大小。
- 若该chunk前一个chunk为malloc chunk,则prev size无实际控制作用,可用作上一个chunk 的数据段来填充数据
- 另外,若前一个chunk为free chunk,且该chunk也为free chunk,则两个free chunk合并为一个free chunk,保留上一个chunk的控制段,下一个chunk变成上一个chunk的数据段,相应的size增大为两个free chunk 的大小。
2 .用户最小申请的内存大小必须是 2 * SIZE 的最小整数倍,且最小为8,那么size对应二进制的最后三位必然为0,为了节省资源和内存,对于后三位赋予特殊意义。
A 记录当前 chunk是否不属于主线程,1 表示不属于,0 表示属于。
M 记录当前 chunk 是否是由 mmap 分配的。1表示是,0表示不是。
P 记录的是前一个chunk的类型,若为0,则前一个chunk为free chunk,若为1,则前一个chunk为malloc chunk,特殊的,对用fast bin里的chunk,P始终为1(因为fast bin需要频繁使用的原因)
chunk的分类:
按状态 按大小 按特定功能
malloced fast top chunk
free small last remainder chunk
targe
tcache
Bin
管理 arena 中空闲 chunk 的结构,以数组的形式存在,数组元素为相应大小的 chunk 链表的链表头,存在于 arena 的 malloc_state 中。
可以理解为桌面的垃圾回收站,可将不需要的放入,需要时又可以拿出来使用(类似回收站的删除和还原)
分类:
unsorted bin
fast bins
small bins
large bins
tcache
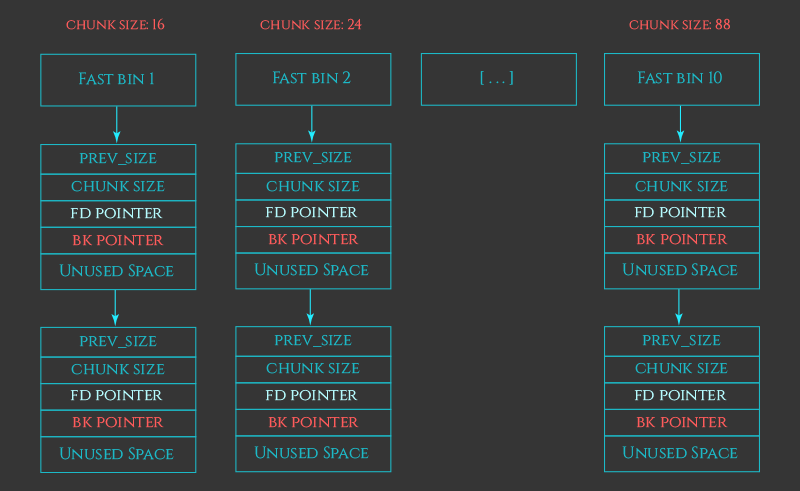
1 .fast bins:
fastbinsY[]
单向列表
LIFO (先进后出,类似栈)
管理 16、24、32、40、48、56、64 Bytes 的 free chunks(32位下默认)
其中的 chunk 的 in_use 位(下一个物理相邻的 chunk 的 P 位)总为1
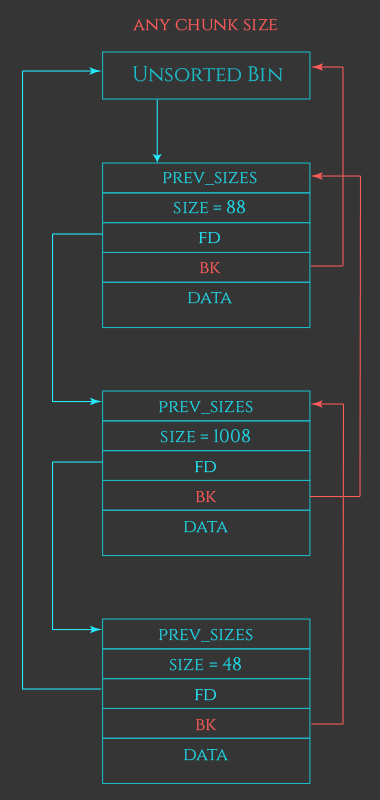
2 . unsorted bin:
bins[1]
管理刚刚释放还为分类的 chunk
可以视为空闲 chunk 回归其所属 bin 之前的缓冲区
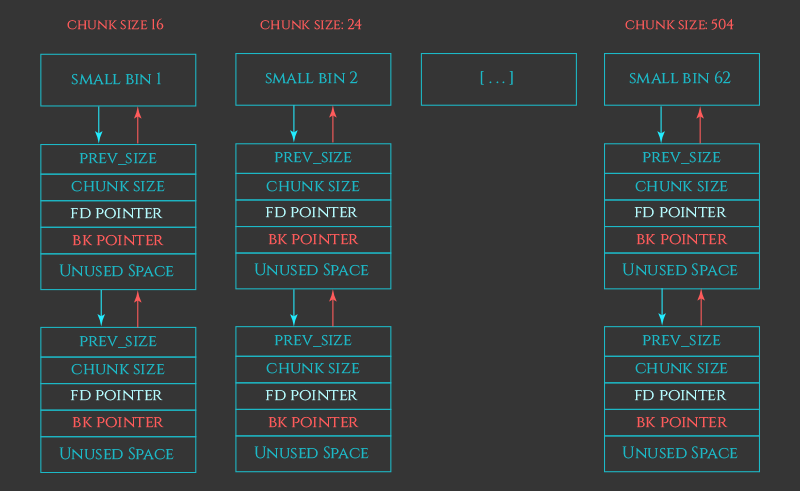
3 .small bins:
- bins[2] ~ bins[63]
- 62 个循环双向链表
- FIFO (先进先出,类似队列)
- 管理 16、24、32、40、 …… 、504 Bytes 的 free chunks(32位下)
- 每个链表中存储的 chunk 大小都一致
4 .large binsL:
- bins[64] ~ bins[126]
- 63 个循环双向链表
- FIFO
- 管理大于 504 Bytes 的 free chunks(32位下)
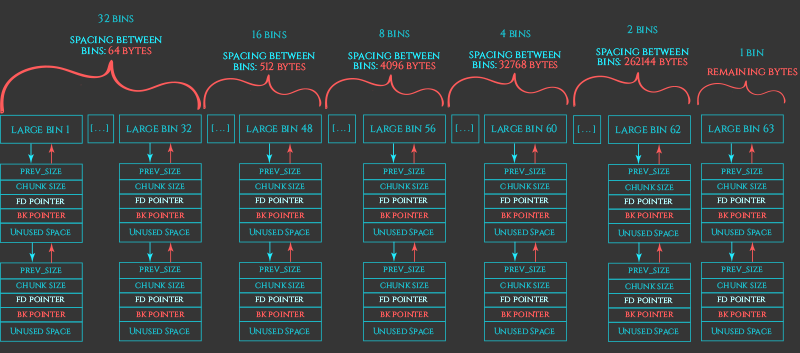
总结:
1 | 首先,对于不同chunk的大小分配到不同的bin中,若大小为16、24、32、40、48、56、64 Bytes 的 free chunks则进入fast bin,其余的进入unsorted bin中 |
堆分配策略
Malloc
- 它根据用户申请的内存块大小以及相应大小 chunk 通常使用的频度(fastbin chunk, small chunk, large chunk),依次实现了不同的分配方法。
- 它由小到大依次检查不同的 bin 中是否有相应的空闲块可以满足用户请求的内存。
- 当所有的空闲 chunk 都无法满足时,它会考虑 top chunk。
- 当 top chunk 也无法满足时,堆分配器才会进行内存块申请。
free
- 它将用户暂且不用的chunk回收给堆管理器,适当的时候还会归还给操作系统。
- 它依据chunk大小来优先试图将free chunk链入tcache或者是fast bin。不满足则链入usorted bin中。
- 在条件满足时free函数遍历usorted bin并将其中的物理相邻的free chunk合并,将相应大小的chunk分类放入small bin或large bin中。
- 除了tcache chunk与fast bin chunk,其它chunk在free时会与其物理相邻的free chunk合并
堆漏洞与其利用
1.double free漏洞
对于一段内存连续两次的free释放,会导致在bin中存放两块相邻且相同的chunk。
图中b为两次对a内存free之间的中间free区域,目的是为了防止两块相同的a的chunk合并为一块。
代码如下:
1 | void *p1 = malloc(a); //a为一快内存大小,如0x20 |
2.use after free
在double free漏洞的举出上进行利用。
假如我们在执行了以上double free后,在fast bin中得到了两块a内存,现在我们有一个指针p指向bin中的内存a,接着又执行了malloc指令,会从fast bin中将原先free的内存再次拿回,但原先p1指向的区域一直没变,此时p通过指向内存a也指向了和p1相同的一块区域。
假如p指针为低级指针,但却可以修改该区域的内容,而具有控制作用的指针p1会把该区域执行,这就使得通过p修改数据的指针却达到了p1执行内容的作用。
例题:
这里我们以 HITCON-training 中的 lab 10 hacknote 为例。
功能分析
我们可以简单分析下程序,可以看出在程序的开头有个 menu 函数,其中有
1 | puts(" 1. Add note "); |
故而程序应该主要有 3 个功能。之后程序会根据用户的输入执行相应的功能。
功能分析 ¶
我们可以简单分析下程序,可以看出在程序的开头有个 menu 函数,其中有
1 | puts(" 1. Add note "); |
故而程序应该主要有 3 个功能。之后程序会根据用户的输入执行相应的功能。
add_note¶
根据程序,我们可以看出程序最多可以添加 5 个 note。每个 note 有两个字段 put 与 content,其中 put 会被设置为一个函数,其函数会输出 content 具体的内容。
1 | unsigned int add_note() |
print_note¶
print_note 就是简单的根据给定的 note 的索引来输出对应索引的 note 的内容。
1 | unsigned int print_note() |
delete_note¶
delete_note 会根据给定的索引来释放对应的 note。但是值得注意的是,在 删除的时候,只是单纯进行了 free,而没有设置为 NULL,那么显然,这里是存在 Use After Free 的情况的。
1 | unsigned int del_note() |
利用分析:
我们可以看到 Use After Free 的情况确实可能会发生,那么怎么可以让它发生并且进行利用呢?需要同时注意的是,这个程序中还有一个 magic 函数,我们有没有可能来通过 use after free 来使得这个程序执行 magic 函数呢?一个很直接的想法是修改 note 的 put 字段为 magic 函数的地址,从而实现在执行 print note 的时候执行 magic 函数。 那么该怎么执行呢?
我们可以简单来看一下每一个 note 生成的具体流程
- 程序申请 8 字节内存用来存放 note 中的 put 以及 content 指针。
- 程序根据输入的 size 来申请指定大小的内存,然后用来存储 content。
1 | +-----------------+ |
那么,note 是一个 fast bin chunk(大小为 16 字节)。我们的目的是希望一个 note 的 put 字段为 magic 的函数地址,那么我们必须想办法让某个 note 的 put 指针被覆盖为 magic 地址。由于程序中只有唯一的地方对 put 进行赋值。所以我们必须利用写 real content 的时候来进行覆盖。
第一种:
具体采用的思路如下
- 申请 note0,real content size 为 16(大小与 note 大小所在的 bin 不一样即可)
- 申请 note1,real content size 为 16(大小与 note 大小所在的 bin 不一样即可)
- 释放 note0
- 释放 note1
- 此时,大小为 16 的 fast bin chunk 中链表为 note1->note0
- 申请 note2,并且设置 real content 的大小为 8,那么根据堆的分配规则
- note2 其实会分配 note1 对应的内存块。 因为8 < 16
- real content 对应的 chunk 其实是 note0。
- 如果我们这时候向 note2 real content 的 chunk 部分写入 magic 的地址,那么由于我们没有 note0 为 NULL。当我们再次尝试输出 note0 的时候,程序就会调用 magic 函数。
脚本如下:
1 | #!/usr/bin/env python |
第二种:
利用图解:
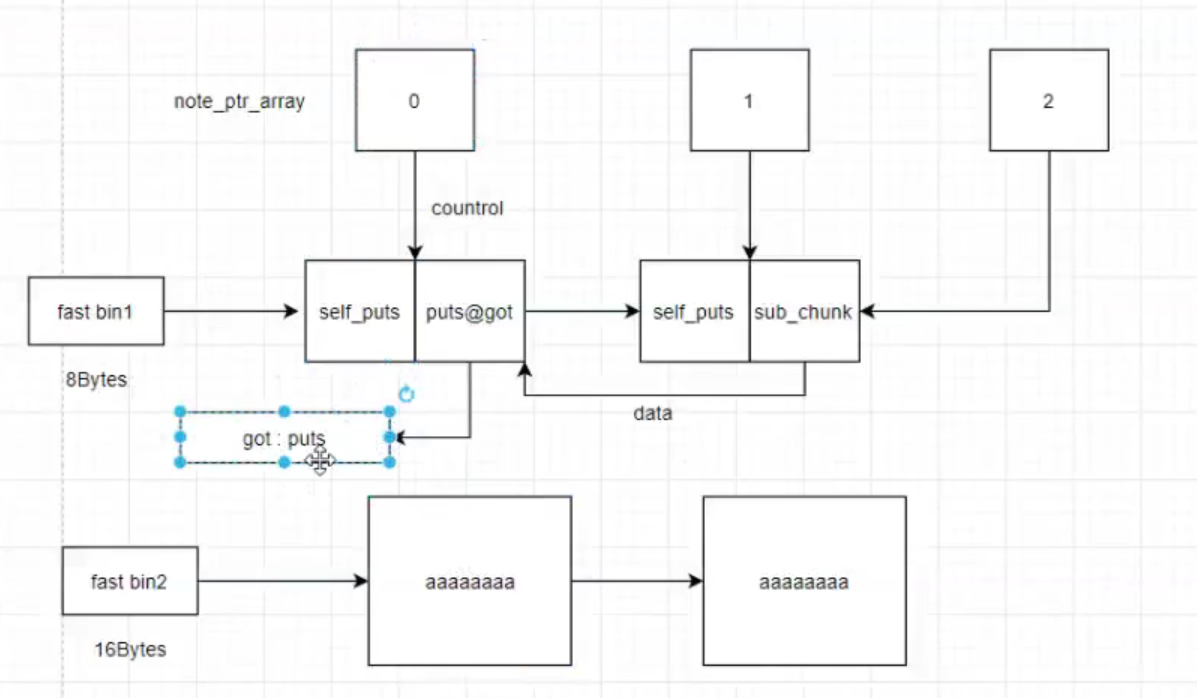
图中0 和 1分别为指针数组的前两项,2为申请的用于篡改内容的指针,对于0的free后再申请会使2指针也指向该空间内存,因为2指向的控制段是1,指向的数据段是0,因此修改2的data段其实修改的是0的控制段,进而让0执行got函数。
进而获取到got表的内容,得到libc中got的真实地址,最后根据偏移量调用system函数。
脚本如下:
1 | from pwn import * |


